XGBoost GPU算法更新
自我们上一次发布首个GPU加速梯度提升算法的文章以来,已经过去了一年半的时间。在这段时间里,XGBoost中的GPU算法一直在持续开发,增加了新功能、更快的算法(快得多得多得多)以及改进的可用性。这篇博客文章与论文XGBoost:可扩展的GPU加速学习[1]一同发布,并描述了其中的一些改进。
基于直方图的树构建算法
决策树构建算法通常通过递归地将一组训练实例在特征空间中分割成越来越小的子集来工作。这些分割是通过搜索训练实例来找到优化训练目标的决策规则。虽然这些算法仍然是有效的线性时间算法,但它们速度较慢,因为在当前层搜索决策规则需要遍历每个训练实例。通过对输入特征进行离散化,算法可以显著加快。
我们主要的决策树构建算法现在是基于直方图的方法,例如[2]、[3]中使用的那种。这意味着我们在输入特征空间上找到分位数,并将训练示例离散化到这个空间中。每个提升迭代中训练示例的梯度可以根据现在离散的特征汇总到直方图“桶”中。找到决策树的最优分割就简化为在离散空间中搜索直方图桶的更简单问题。
最终结果是一个显著更快、更内存高效的算法,同时仍然保持其准确性。
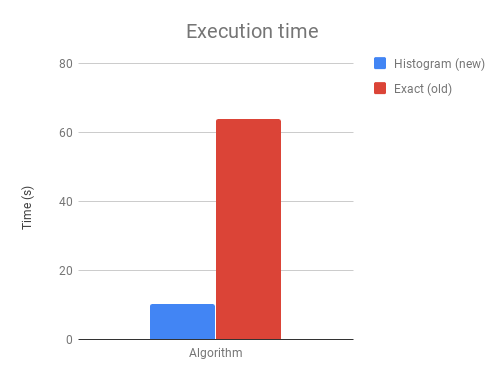
上图显示了在具有500个提升迭代的1M*50二分类问题上的执行时间差异。
多GPU支持
我们的直方图算法使用NCCL库提供了完整的多GPU支持,用于GPU之间的可扩展通信。这意味着我们可以做一些事情,比如在具有八个GPU的AWS P3实例上运行XGBoost。下表显示了在包含1.15亿行数据的Airline数据集上,随着GPU数量增加时的运行时长。
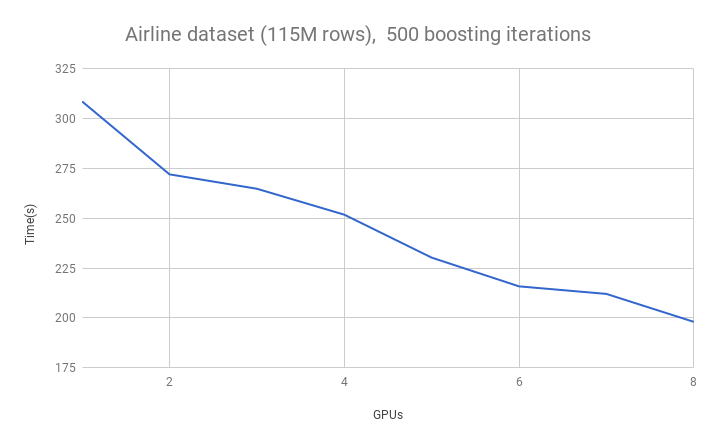
由于高效的AllReduce通信原语,通信吞吐量随GPU数量增加而保持恒定。通信成本也与训练示例的数量无关,因为只共享直方图摘要统计信息。数据集在GPU之间均匀分布。这使我们能够扩展到无法容纳在单个GPU上的数据集,并利用多GPU系统的全部设备内存容量。
数据压缩
我们当前的算法也比[4]中发布的原始算法内存效率高得多。这主要通过在离散化后对输入矩阵进行数据压缩来实现。例如,如果每个特征使用256个直方图桶,共有50个特征,则整个输入矩阵中只有256*50个唯一特征值。通过使用位压缩,我们可以在稀疏的CSR格式中,每个矩阵元素仅使用log2(256*50)=14位进行存储。作为比较,原始的CSR存储格式通常每个矩阵元素至少需要64位。
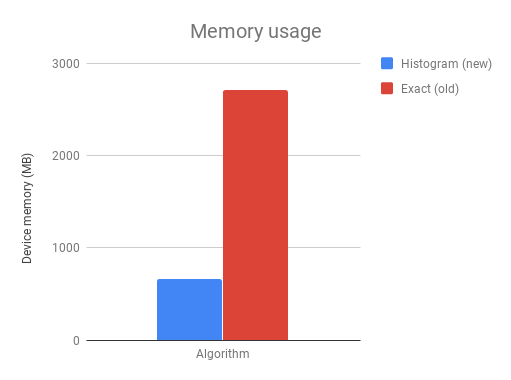
上图显示了直方图算法和精确算法在1M*50二分类问题上的设备内存需求。
GPU预测和梯度计算算法
传统上,树构建算法占用了梯度提升算法的大部分时间。在我们开发出显著更快的树算法后,这种情况发生了改变,梯度提升过程的其他部分开始产生瓶颈。
梯度提升中,为了计算下一次迭代的梯度(残差),每迭代都会进行预测。用户可能还需要监控测试集或验证集上的性能。这累积起来在CPU上产生了大量的计算。我们将此计算映射到GPU内核,将预测时间提高了5-10倍。请注意,此改进是针对已存储在GPU上的内存。当用于未见过的数据集时,预测算法会因为将矩阵复制到GPU所需的时间而变慢(即,这些预测算法是为训练而设计,而非模型部署)。
我们还为某些任务引入了GPU加速的目标函数计算。通过将目标函数设置为以下之一,可以启用这些功能:
"gpu:reg:linear", "gpu:reg:logistic", "gpu:binary:logistic", gpu:binary:logitraw"
将梯度提升流水线的更多部分移到设备上可以消除计算瓶颈,并减少在CPU和GPU之间通过有限带宽的PCIe总线来回复制内存的需求。最终我们希望将整个流水线都移到设备上。
与其他GBM算法的基准测试
以下是在8 GPU云计算实例上与其他梯度提升算法的一些基准测试。重现这些基准测试的说明可以在这里找到。
| YearPrediction | Synthetic | Higgs | Cover Type | Bosch | Airline | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 时间(秒) | RMSE | 时间(秒) | RMSE | 时间(秒) | 准确率 | 时间(秒) | 准确率 | 时间(秒) | 准确率 | 时间(秒) | 准确率 | |
| xgb-cpu-hist | 216.71 | 8.8794 | 580.72 | 13.6105 | 509.29 | 74.74 | 3532.26 | 89.2 | 810.36 | 99.45 | 1948.26 | 74.94 |
| xgb-gpu-hist | 30.39 | 8.8799 | 43.14 | 13.4606 | 38.41 | 74.75 | 107.70 | 89.34 | 27.97 | 99.44 | 110.29 | 74.95 |
| lightgbm-cpu | 30.82 | 8.8777 | 463.79 | 13.585 | 330.25 | 74.74 | 186.27 | 89.28 | 162.29 | 99.44 | 916.04 | 75.05 |
| lightgbm-gpu | 25.39 | 8.8777 | 576.67 | 13.585 | 725.91 | 74.7 | 383.03 | 89.26 | 409.93 | 99.44 | 614.74 | 74.99 |
| cat-cpu | 39.93 | 8.9933 | 426.31 | 9.387 | 393.21 | 74.06 | 306.17 | 85.14 | 255.72 | 99.44 | 2949.04 | 72.66 |
| cat-gpu | 10.15 | 9.0637 | 36.66 | 9.3805 | 30.37 | 74.08 | 不适用 | 不适用 | 不适用 | 不适用 | 303.36 | 72.77 |
安装和使用
从XGBoost 0.72版本开始,在Linux平台上使用GPU支持安装Python非常简单,只需:
pip install xgboost
其他平台的用户仍然需要从源代码构建,尽管预构建的Windows软件包已在规划中。
要使用我们新的快速算法,只需在现有的XGBoost脚本中将“tree_method”参数设置为“gpu_hist”。
使用XGBoost Python API和sklearn API的简单示例
import xgboost as xgb
from sklearn.datasets import load_boston
boston = load_boston()
# XGBoost API example
params = {'tree_method': 'gpu_hist', 'max_depth': 3, 'learning_rate': 0.1}
dtrain = xgb.DMatrix(boston.data, boston.target)
xgb.train(params, dtrain, evals=[(dtrain, "train")])
# sklearn API example
gbm = xgb.XGBRegressor(n_estimators=10, tree_method='gpu_hist')
gbm.fit(boston.data, boston.target, eval_set=[(boston.data, boston.target)])
输出
[01:12:20] Allocated 0MB on [0] Tesla K80, 11352MB remaining.
[01:12:20] Allocated 0MB on [0] Tesla K80, 11351MB remaining.
[01:12:20] Allocated 0MB on [0] Tesla K80, 11350MB remaining.
[0] train-rmse:21.6024
[1] train-rmse:19.5554
[2] train-rmse:17.7153
[3] train-rmse:16.0624
[4] train-rmse:14.5719
[5] train-rmse:13.2413
[6] train-rmse:12.0342
[7] train-rmse:10.9578
[8] train-rmse:9.97791
[9] train-rmse:9.10676
[01:12:20] Allocated 0MB on [0] Tesla K80, 11352MB remaining.
[01:12:20] Allocated 0MB on [0] Tesla K80, 11351MB remaining.
[01:12:20] Allocated 0MB on [0] Tesla K80, 11350MB remaining.
[01:12:20] Allocated 0MB on [0] Tesla K80, 11350MB remaining.
[0] validation_0-rmse:21.6024
[1] validation_0-rmse:19.5554
[2] validation_0-rmse:17.7153
[3] validation_0-rmse:16.0624
[4] validation_0-rmse:14.5719
[5] validation_0-rmse:13.2413
[6] validation_0-rmse:12.0342
[7] validation_0-rmse:10.9578
[8] validation_0-rmse:9.97791
[9] validation_0-rmse:9.10676
作者
Rory Mitchell是怀卡托大学的博士生,并在H2O.ai工作。
特别感谢XGBoost GPU项目的所有贡献者,特别是Nvidia的Andrey Adinets和Thejaswi Rao,他们在算法改进方面做出了重要贡献。
参考文献
[1] Rory Mitchell, Andrey Adinets, Thejaswi Rao: “XGBoost: Scalable GPU Accelerated Learning”, 2018; http://arxiv.org/abs/1806.11248。
[2] Keck, Thomas. “FastBDT: A speed-optimized and cache-friendly implementation of stochastic gradient-boosted decision trees for multivariate classification.” arXiv preprint arXiv:1609.06119 (2016).
[3] Ke, Guolin, et al. “Lightgbm: A highly efficient gradient boosting decision tree.” Advances in Neural Information Processing Systems. 2017.
[4] Mitchell, Rory, and Eibe Frank. “Accelerating the XGBoost algorithm using GPU computing.” PeerJ Computer Science 3 (2017): e127.