GPU 加速的 XGBoost
更新 2016/12/23: 由于错误的编译器标志,我们的一些基准测试不准确。这些都已在下面更新。
决策树学习和梯度提升直到最近一直是多核 CPU 的领域。在这里,我们展示了一个为 XGBoost 库提供 GPU 加速的新插件。该插件为大型数据集提供了比多核 CPU 显著的加速。
该插件可在以下位置找到: https://github.com/dmlc/xgboost/tree/master/plugin/updater_gpu
在讨论 GPU 插件之前,我们简要解释一下 XGBoost 算法。
用于分类和回归的 XGBoost
XGBoost 是解决监督学习环境中分类和回归问题的强大工具。它是广义梯度提升算法的一种实现,旨在提供高性能、多核可扩展性和分布式机器可扩展性。
梯度提升算法是一种集成学习技术,它构建了许多预测模型。这些较小的模型共同产生的预测比任何单个模型都要强大得多。特别是对于梯度提升,我们按顺序创建这些较小的模型,其中每个新模型直接解决先前模型的弱点。
虽然许多类型的模型都可以用于提升算法,但在实践中,我们几乎总是使用决策树。下面我们展示一个决策树的例子,该决策树根据一个人的年龄和性别预测他们是否喜欢电脑游戏。给定一个要预测的新示例,我们在树的根部输入该示例,并遵循决策规则直到到达一个带有预测的叶节点。
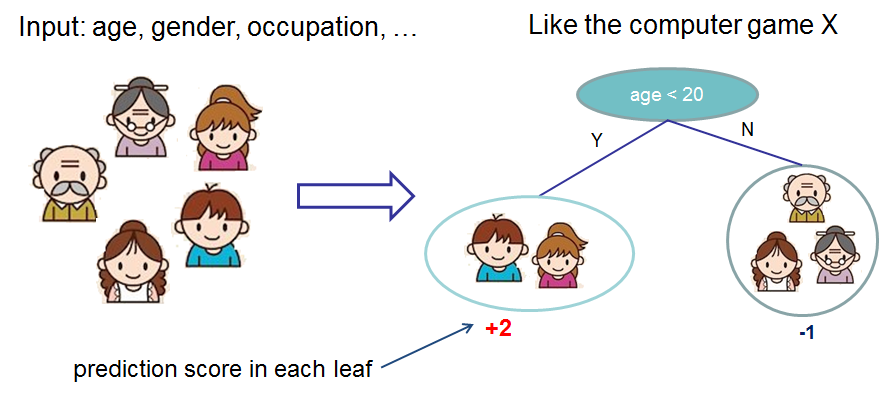
给定一个由多棵树组成的集成,我们可以组合预测以获得更强的预测结果。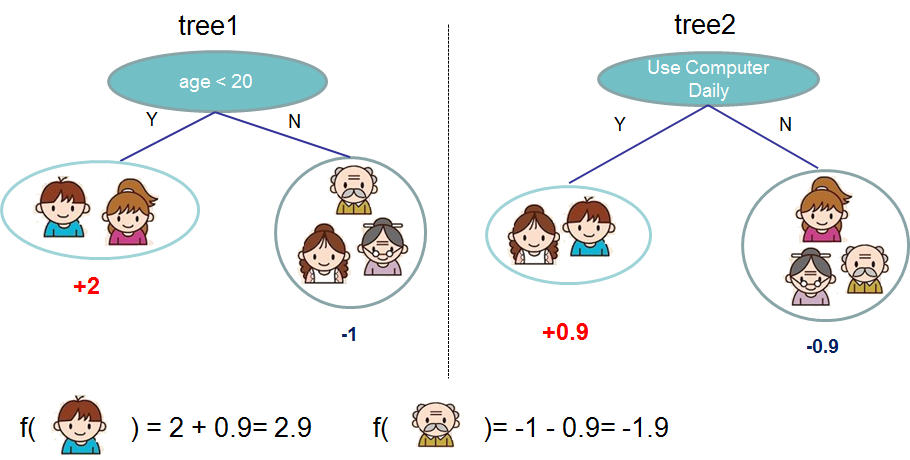
使用 XGBoost 创建上面那样的数千个模型并不罕见,每个模型都会在前一个模型的结果基础上增量改进。
您可能会问,当机器学习似乎都与深度学习相关时,我为什么要关注梯度提升?答案是它对结构化数据非常有效。
XGBoost 在 Kaggle 数据科学社区中取得了巨大成功,甚至“几乎赢得了结构化数据类别中的所有比赛”。
GPU 加速
使用 XGBoost 执行机器学习任务可能需要数小时。为了获得最先进的预测结果,我们通常希望创建数千棵树并测试许多不同的参数组合。如果用户能够利用他们强大但闲置的显卡来加速这项任务,那就太好了。
GPU 一次可以启动数千个并行线程,并且可以为许多可被描述为并行算法的计算密集型任务提供显著的加速。
幸运的是,决策树构建算法可以并行化,从而使我们能够加速提升迭代。请注意,我们并行构建单个树 - 提升过程本身具有串行依赖性。
它有多快?
以下基准测试显示了 GPU 与多核 CPU 进行 500 次提升迭代的性能比较。新款 Pascal Titan X 相较于 i7 CPU 显示出高达 5.57 倍的良好性能提升。Titan 也能够在其 12GB 内存中处理整个 1000 万行的 Higgs 数据集。
| 数据集 | 实例数 | 特征数 | i7-6700K | Titan X (pascal) | 加速比 |
|---|---|---|---|---|---|
| Yahoo LTR | 473,134 | 700 | 877 | 277 | 3.16 |
| Higgs | 10,500,000 | 28 | 14504 | 3052 | 4.75 |
| Bosch | 1,183,747 | 968 | 3294 | 591 | 5.57 |
我们还在 Yahoo 排序学习数据集上测试了 Titan X 与配备 2 个 Xeon E5-2695v2 CPU(共 24 个核心)的服务器的对比。GPU 的性能比 CPU 好约 1.2 倍。考虑到 Titan X 售价 1200 美元,而 2 个 Xeon CPU 售价近 5000 美元,这是一个不错的结果。

它是如何工作的?
XGBoost 算法需要在训练集中的每个可能分裂点扫描梯度/Hessian 值,并使用这些部分和来评估分裂的质量。GPU XGBoost 算法利用快速并行前缀和操作扫描所有可能的分裂点,并利用并行基数排序重新划分数据。它为给定的提升迭代一次构建一层决策树,同时在 GPU 上并发处理整个数据集。
该算法还在两种模式之间切换。第一种模式使用专门的多扫描/多规约操作以交错顺序处理节点组。当树较低层级叶节点较少时,这提供了更好的性能。在后面的层级,我们切换到使用基数排序重新划分数据并执行更传统的扫描/规约操作。
我如何使用它?
要使用 GPU 算法,请添加单个参数
# Python example
param['updater'] = 'grow_gpu'
必须使用 cmake 构建系统从源代码构建 XGBoost,请遵循此处的说明。
目前,该插件可以通过 Python 或 CLI 接口使用。提供了一个演示,展示了如何使用 GPU 算法加速大型数据集上的交叉验证任务。
关于作者
XGBoost GPU 插件由 Rory Mitchell 贡献。该项目是怀卡托大学硕士学位论文的一部分。
非常感谢 XGBoost 的作者和贡献者们!