XGBoost R 包介绍
介绍
XGBoost 是一个为提升树(boosting trees)算法设计和优化的库。梯度提升树模型最初由 Friedman 等人提出。XGBoost 的底层算法与之类似,具体来说,它是经典 gbm 算法的扩展。通过使用多线程和施加正则化,XGBoost 能够利用更多计算能力并获得更准确的预测。有关模型的详细信息,请参阅本教程。
其准确性的一个证据是,在 Kaggle 举办的机器学习挑战赛中,超过一半的获胜解决方案都使用了 XGBoost。我们准备了一份(不完整)的获胜解决方案列表。
存在各种高级接口。目前,XGBoost 在 C++、R、Python、Julia、Java 和 Scala 中都有接口。XGBoost 中的核心功能是用 C++ 实现的,因此在不同接口之间共享模型很容易。本文将重点介绍 R 包 xgboost,它具有友好的用户界面和全面的文档。根据 RStudio CRAN 镜像的统计数据,该包在上个月的下载量已超过 4000 次。
R 包 xgboost 获得了 2016 年 John M. Chambers 统计软件奖。从工作伊始,我们的目标就是创建一个能够为用户带来便利和愉悦的软件包。因此,我们将介绍 xgboost R 包的一些详细信息(我们认为)用户会想知道。
一分钟新手指南
xgboost 在 CRAN 和 Github 上均可用。要从 CRAN 安装稳定/预编译版本,只需运行
install.packages('xgboost')
您也可以从我们每周更新的 drat repo 安装
install.packages("drat", repos="https://cran.rstudio.com")
drat:::addRepo("dmlc")
install.packages("xgboost", repos="http://dmlc.ml/drat/", type="source")
为了运行机器学习算法,我们首先需要一个数据集。xgboost 有一个关于蘑菇的演示数据集。该数据集记录了不同蘑菇物种的生物学属性,目标是预测它是否有毒。用户可以使用以下命令加载数据
require(xgboost)
data(agaricus.train, package='xgboost')
data(agaricus.test, package='xgboost')
train <- agaricus.train
test <- agaricus.test
每个变量都是一个包含两项的 list:label 和 data。下一步是将这些数据提供给 xgboost。除了数据,我们还需要用一些其他参数来训练模型
nrounds:最终模型中的决策树数量objective:要使用的训练目标,其中“binary:logistic”表示二元分类器。
最简单的训练命令如下
model <- xgboost(data = train$data, label = train$label,
nrounds = 2, objective = "binary:logistic")
## [0] train-error:0.000614
## [1] train-error:0.001228
我们可以轻松地在测试数据集上进行预测
preds = predict(model, test$data)
有时使用交叉验证来检验我们的模型非常重要。在 xgboost 中,我们提供了一个函数 xgb.cv 来实现此目的。基本上,用户只需从 xgboost 中复制所有内容,并指定 nfold
cv.res <- xgb.cv(data = train$data, label = train$label, nfold = 5,
nrounds = 2, objective = "binary:logistic")
## [0] train-error:0.000921+0.000343 test-error:0.001228+0.000687
## [1] train-error:0.001075+0.000172 test-error:0.001228+0.000687
要了解更多关于 xgboost 用法的详细信息,请访问我们的教程。
高效的算法
如果您有在大型数据集上训练模型的经验,那么您可能会同意等待训练完成是很无聊的。时间是一种资源,因此学习算法的训练速度很重要。这取决于算法和实现。我们在构建 xgboost 时非常关注这些问题,因此我们确信 xgboost 是梯度提升算法中最快的学习算法之一。其高效的原因是:
- 计算部分是用 C++ 实现的。
- 它可以在单机上多线程运行。
- 它在训练算法之前对数据进行预处理。
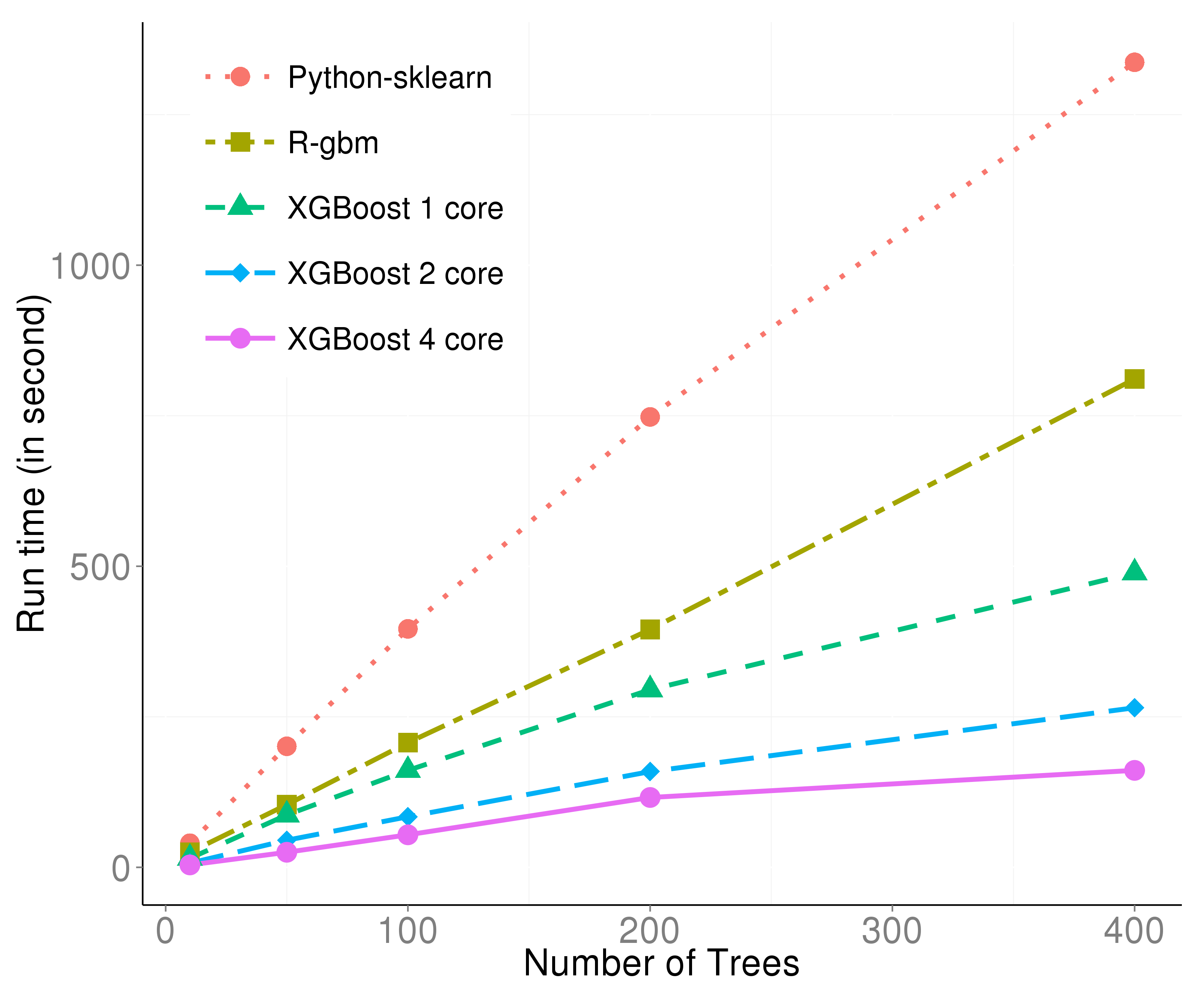
这张图使用来自希格斯玻色子竞赛的数据集生成。可以从两个方面来描述:
- 仅使用一个线程时,预处理和 C++ 的效果已经很明显。
- 多线程效率与线程数几乎呈线性关系,进一步提升了效率。
便捷的接口
作为 xgboost 的开发者,我们也是 xgboost 的重度用户。我们非常重视使用此工具的体验。在开发过程中,我们努力将软件包打造成用户友好的。以下是几个我们想分享的细节,请点击标题访问示例代码。
自定义目标函数
xgboost 可以接受自定义目标函数。这意味着可以训练模型以优化用户定义的目标。这在其他工具中并不常见,因为大多数算法都绑定了特定的目标函数。使用 xgboost,可以训练一个模型来最大化在正确方向上的工作。
我们以对数似然作为演示。我们定义以下函数来计算损失函数的一阶和二阶梯度
loglossobj <- function(preds, dtrain) {
# dtrain is the internal format of the training data
# We extract the labels from the training data
labels <- getinfo(dtrain, "label")
# We compute the 1st and 2nd gradient, as grad and hess
preds <- 1/(1 + exp(-preds))
grad <- preds - labels
hess <- preds * (1 - preds)
# Return the result as a list
return(list(grad = grad, hess = hess))
}
然后我们训练模型如下
model <- xgboost(data = train$data, label = train$label,
nrounds = 2, objective = loglossobj, eval_metric = "error")
## [0] train-error:0.001228
## [1] train-error:0.001228
结果应该等同于 objective = "binary:logistic"。
提前停止
常见的情况是,当我们不确定需要多少棵树时,我们会先尝试一些数字并检查结果。如果尝试的数字太小,我们需要将其增大;如果数字太大,我们就是在浪费时间等待终止。通过设置参数 early_stopping,如果性能在迭代过程中变差,xgboost 将终止训练过程。
bst <- xgb.cv(data = train$data, label = train$label, nfold = 5,
nrounds = 20, objective = "binary:logistic",
early.stop.round = 3, maximize = FALSE)
## [0] train-error:0.000921+0.000343 test-error:0.001228+0.000686
## [1] train-error:0.001228+0.000172 test-error:0.001228+0.000686
## [2] train-error:0.000653+0.000442 test-error:0.001075+0.000875
## [3] train-error:0.000422+0.000416 test-error:0.000767+0.000940
## [4] train-error:0.000192+0.000429 test-error:0.000460+0.001029
## [5] train-error:0.000192+0.000429 test-error:0.000460+0.001029
## [6] train-error:0.000000+0.000000 test-error:0.000000+0.000000
## [7] train-error:0.000000+0.000000 test-error:0.000000+0.000000
## [8] train-error:0.000000+0.000000 test-error:0.000000+0.000000
## [9] train-error:0.000000+0.000000 test-error:0.000000+0.000000
## Stopping. Best iteration: 7
这里我们正在进行交叉验证。early.stop.round = 3 表示如果性能连续 3 步没有改善,程序将停止。maximize = FALSE 表示我们的目标不是最大化评估指标,二元分类的默认评估指标是分类错误率。我们可以看到,即使我们要求模型训练 20 棵树,它也在性能达到完美后停止了。
继续训练
有时我们可能想先尝试 1000 次迭代并检查结果,然后决定是否需要再进行 1000 次。通常第二步只能从头开始再次完成。在 xgboost 中,用户可以在之前的模型上继续训练,因此第二步只会花费您额外迭代的时间。我们能够做到这一点的理论原因是因为每棵树只根据前面树的预测结果进行训练。一旦我们通过当前的树获得了预测结果,我们就可以开始训练下一棵。
此功能涉及 xgboost 的内部数据格式:xgb.DMatrix。xgb.DMatrix 对象包含特征、目标和其他辅助信息,例如权重、缺失值。
首先,让我们为这些数据定义一个 xgb.DMatrix 对象
dtrain <- xgb.DMatrix(train$data, label = train$label)
接下来我们用它来训练模型
model <- xgboost(data = dtrain, nrounds = 2, objective = "binary:logistic")
## [0] train-error:0.000614
## [1] train-error:0.001228
请注意,我们在 dtrain 对象中包含了 label。然后我们对当前训练数据进行预测
pred_train <- predict(model, dtrain, outputmargin=TRUE)
这里的参数 outputmargin 表示我们不需要对结果进行逻辑变换。
最后,我们将之前的预测结果作为额外信息添加到对象 dtrain 中,以便训练算法知道从哪里开始。
setinfo(dtrain, "base_margin", pred_train)
## [1] TRUE
现在观察结果如何变化
model <- xgboost(data = dtrain, nrounds = 2, objective = "binary:logistic")
## [0] train-error:0.000614
## [1] train-error:0.000614
处理缺失值
缺失值在真实世界数据集中很常见。处理缺失值没有适用于所有情况的规则,因为值缺失的原因可能多种多样。在 xgboost 中,我们选择了一种“软”方法来处理缺失值。当使用带有缺失值的特征进行分割时,xgboost 会为缺失值指定一个**方向**,而不是一个数值。具体来说,xgboost 会将所有带有缺失值的数据点分别导向左侧和右侧,然后选择在目标函数方面增益较高的方向。
要启用此功能,只需设置参数 missing 来标记缺失值的标签。为了演示这一点,我们可以手动创建一个带有缺失值的数据集。
dat <- matrix(rnorm(128), 64, 2)
label <- sample(0:1, nrow(dat), replace = TRUE)
for (i in 1:nrow(dat)) {
ind <- sample(2, 1)
dat[i, ind] <- NA
}
然后我们只需在代码中指定缺失值标记 NA
model <- xgboost(data = dat, label = label, missing = NA,
nrounds = 2, objective = "binary:logistic")
## [0] train-error:0.281250
## [1] train-error:0.281250
实际上,missing 的默认值就是 NA,因此在标准情况下我们甚至不需要指定它。
模型检查
xgboost 使用的模型是梯度提升树,因此一个模型通常包含多个树模型。一个典型的由两棵树组成的集成模型看起来像这样
bst <- xgboost(data = train$data, label = train$label, max.depth = 2,
eta = 1, nthread = 2, nround = 2, objective = "binary:logistic")
xgb.plot.tree(feature_names = agaricus.train$data@Dimnames[[2]], model = bst)
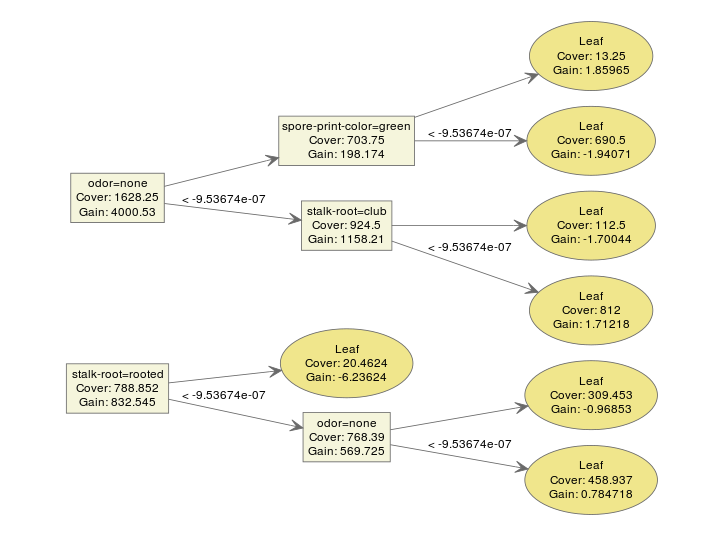
我们可以很容易地对模型进行解释。xgboost 提供了一个函数 xgb.plot.tree 来绘制模型,以便我们可以直接了解结果。
然而,如果我们有更多的树呢?
bst <- xgboost(data = train$data, label = train$label, max.depth = 2,
eta = 1, nthread = 2, nround = 10, objective = "binary:logistic")
xgb.plot.tree(feature_names = agaricus.train$data@Dimnames[[2]], model = bst)
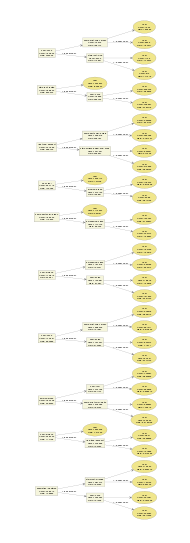
事情开始变得混乱了。我们甚至很难检查图中的每个细节。有太多条件时不容易讲清楚故事。
多合一图
在 xgboost 中,我们提供了一个函数 xgb.plot.multi.trees 将多棵树集成为一棵!此功能受到了这篇博客文章的启发:https://wellecks.wordpress.com/2015/02/21/peering-into-the-black-box-visualizing-lambdamart/。这是通过以下观察实现的
- 几乎所有集成模型中的树都具有相同的形状。如果最大深度确定,则所有二叉树都如此。
- 在每个节点上都会出现多个特征。但我们可以通过每个特征的频率来描述它,从而创建一个频率表。
这是一个“集成”树可视化的示例。
bst <- xgboost(data = train$data, label = train$label, max.depth = 15,
eta = 1, nthread = 2, nround = 30, objective = "binary:logistic",
min_child_weight = 50)
xgb.plot.multi.trees(model = bst, feature_names = agaricus.train$data@Dimnames[[2]], features.keep = 3)
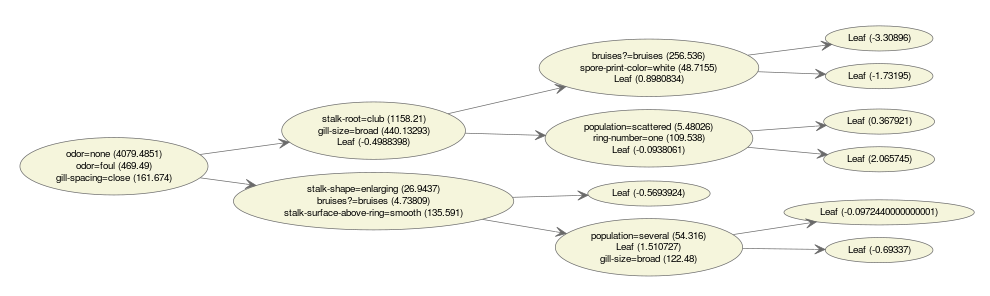
节点中的文本表示在此位置选择的特征的分布。如果我们将鼠标悬停在节点上,我们可以获取路径信息。
特征重要性
如果树太深,或者特征数量很大,那么要找到任何有用的模式仍然很困难。一种简化的方法是检查特征重要性。在 xgboost 中,我们如何定义特征重要性?
在 xgboost 中,每次分割都试图找到最佳特征和分割点来优化目标。我们可以计算每个节点的增益,这是所选特征的贡献。最后,我们查看所有树,并将每个特征的所有贡献加起来,将其视为重要性。如果特征数量很大,我们也可以在绘制之前对特征进行聚类。这是使用函数 xgb.plot.importance 绘制的特征重要性图示例
bst <- xgboost(data = train$data, label = train$label, max.depth = 2,
eta = 1, nthread = 2, nround = 2,objective = "binary:logistic")
importance_matrix <- xgb.importance(agaricus.train$data@Dimnames[[2]], model = bst)
xgb.plot.importance(importance_matrix)
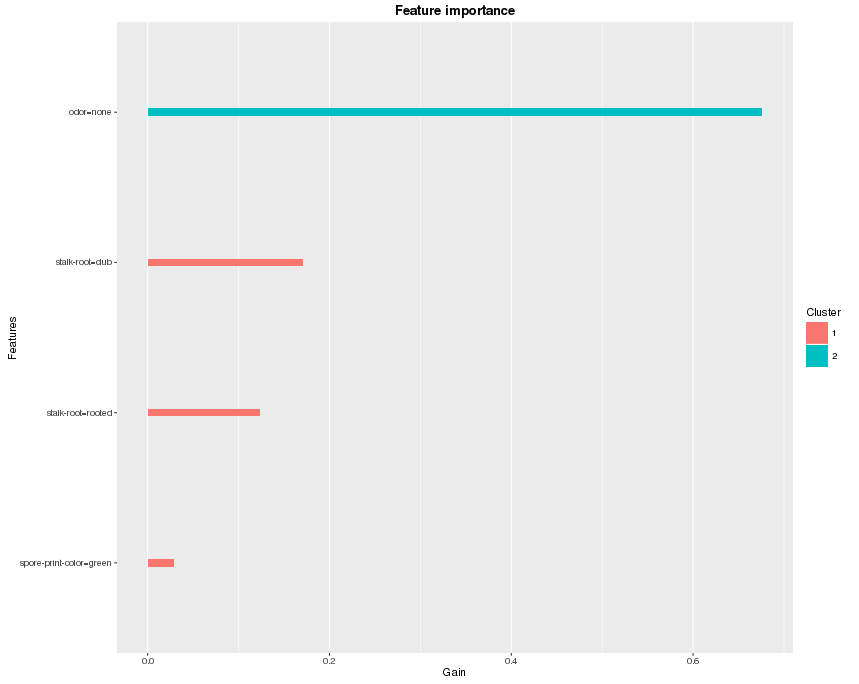
深度
除了绘制所有树之外,还有不止一种方法可以理解树的结构。由于它们都是二叉树,如果我们知道每个叶子的深度,我们就可以在脑海中形成清晰的图像。函数 xgb.plot.deepness 受这篇博客文章启发:http://aysent.github.io/2015/11/08/random-forest-leaf-visualization.html。
通过函数 xgb.plot.deepness,我们可以获得两个图,它们根据树的深度变化总结了叶子的分布。
bst <- xgboost(data = train$data, label = train$label, max.depth = 15,
eta = 1, nthread = 2, nround = 30, objective = "binary:logistic",
min_child_weight = 50)
xgb.plot.deepness(model = bst)
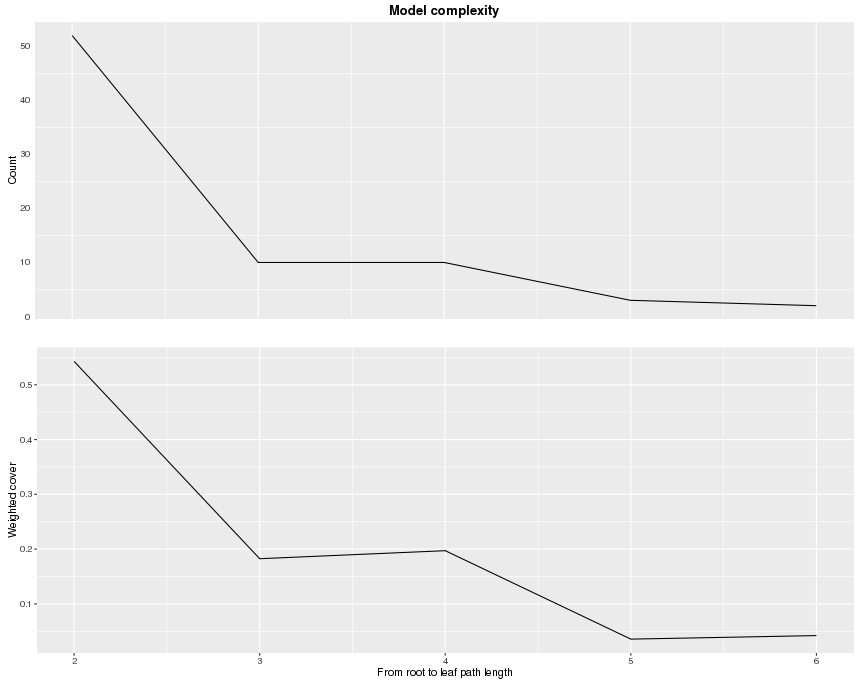
上面的图显示了每层深度的叶子数量。下面的图显示了每个叶子的归一化加权覆盖(实例加权和)。从这些信息中,我们可以看到第 5 层和第 6 层实际上没有多少叶子。为了避免过拟合,我们可以限制树的深度为一个较小的数字。
进一步阅读
这篇博文只是让您对 XGBoost 有一个初步了解,而关于它还有很多更令人兴奋的资源!您可以随意浏览列表,寻找您喜欢的任何内容。
- XGBoost 的 GitHub 仓库
- XGBoost 的全面文档网站
- 梯度提升模型的介绍
- R 包教程
- 参数介绍
- Awesome XGBoost,一份精选的关于 XGBoost 用例的示例、教程、博客列表
如有任何疑问,请随时查看问题论坛。